Meta에서 128K 컨택스트 길이를 가지고 8개의 언어를 지원하는 Llama 3.1 405B 모델을 소개 하였습니다. 사용자가 자신의 요구 사항과 애플리케이션에 맞게 모델을 완전히 사용자 정의하고, 새로운 데이터 세트에서 학습하고, 추가 미세 조정을 수행할 수 있으며 이러한 결과를 Meta와 공유하지 않아도 됩니다.
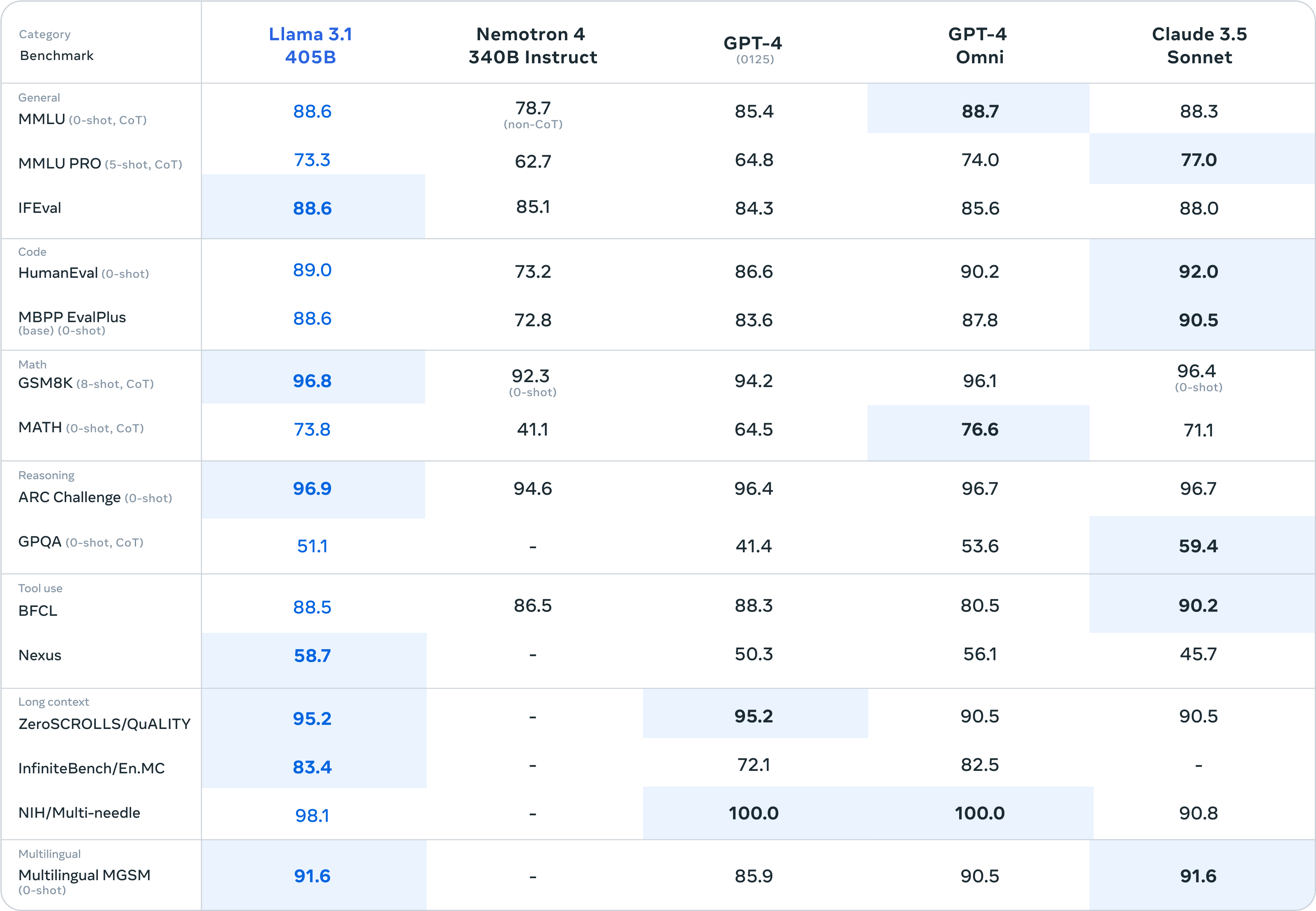
성능 측면에서는 GPT-4, GPT-4o, Claude 3.5 Sonnet을 포함한 다양한 모델들과 비교했을 때 비슷하거나 나은 수준을 보여주고 있습니다.
물론 이런 대규모 모델을 개인 컴퓨터에서 빌드하고 실행하기 위한 다양한 조치도 포함되어 있습니다. 8B 및 70B 모델 사용자도 섭섭하지 않게 업그레이드된 버전을 제공한다고 합니다.
Meta는 다른 경쟁사와는 다르게 Open source 주의를 내세워 많은 사람들이 모델 개발에 참여하도록 유도하고 있으며, 온 디바이스 영역에 대해 지속적인 관심을 가지고 있습니다. 이런 스탠스가 주류로 자리 잡기 위해서는 높은 성능과 함께 개인 기기에서도 큰 무리 없이 동작해야 할텐데요. Meta가 이 스탠스를 유지할지 지켜보는 것도 좋은 관심사가 될 것으로 보입니다.
출처: Introducing Llama 3.1: Our most capable models to date (meta.com)
Introducing Llama 3.1: Our most capable models to date
For this release, we evaluated performance on over 150 benchmark datasets that span a wide range of languages. In addition, we performed extensive human evaluations that compare Llama 3.1 with competing models in real-world scenarios. Our experimental eval
ai.meta.com
주요내용
- Meta는 공개적으로 접근 가능한 AI에 전념합니다. Mark Zuckerberg의 편지에서 오픈 소스가 개발자, Meta, 그리고 세상에 왜 좋은지 자세히 알아보세요.
- 모든 사람에게 오픈 인텔리전스를 제공하는 최신 모델은 컨텍스트 길이를 128K로 확장하고 8개 언어에 대한 지원을 추가하며 최초의 프런티어 레벨 오픈 소스 AI 모델인 Llama 3.1 405B를 포함합니다.
- Llama 3.1 405B는 최고의 폐쇄 소스 모델과 맞먹는 탁월한 유연성, 제어 및 최첨단 기능을 갖춘 독보적인 클래스입니다. 새로운 모델을 통해 커뮤니티는 합성 데이터 생성 및 모델 경량화와 같은 새로운 워크플로를 잠금 해제할 수 있습니다.
- 참조 시스템을 포함하여 모델과 함께 작동하는 더 많은 구성 요소를 제공하여 Llama를 시스템으로 계속 구축하고 있습니다. 개발자에게 사용자 정의 에이전트와 새로운 유형의 에이전트 동작을 만들 수 있는 도구를 제공하고자 합니다. Llama Guard 3 및 Prompt Guard를 포함한 새로운 보안 및 안전 도구로 이를 강화하여 책임감 있게 구축할 수 있도록 돕습니다. 또한 타사 프로젝트가 Llama 모델을 더 쉽게 활용할 수 있도록 하는 표준 인터페이스인 Llama Stack API에 대한 RFC도 발표합니다.
- 이 생태계는 AWS, NVIDIA, Databricks, Groq, Dell, Azure, Google Cloud, Snowflake를 포함한 25개 이상의 파트너가 첫날부터 서비스를 제공하면서 준비가 완료되었습니다.
- WhatsApp과 meta.ai에서 미국에서 Llama 3.1 405B를 사용해 보고 어려운 수학 또는 코딩 질문을 해보세요.
오늘날까지 오픈소스 대규모 언어 모델은 기능과 성능 면에서 대부분 폐쇄형 대응 모델보다 뒤처져 있었습니다. 이제 우리는 오픈소스가 선두를 달리는 새로운 시대를 열고 있습니다. 우리는 Meta Llama 3.1 405B를 공개적으로 출시합니다. 이는 세계에서 가장 크고 가장 유능한 오픈소스 기반 모델이라고 믿습니다. 지금까지 모든 Llama 버전의 총 다운로드 수가 3억 건이 넘었으므로 이제 시작에 불과합니다.
Llama 3.1 소개
Llama 3.1 405B는 일반 지식, 조종성, 수학, 도구 사용 및 다국어 번역, 그리고 최첨단 기능 면에서 최고 AI 모델과 경쟁하는 최초의 공개 모델입니다. 405B 모델이 출시됨에 따라 전례 없는 성장 및 탐색 기회와 함께 혁신을 가속화할 준비가 되었습니다. 최신 세대의 Llama가 새로운 애플리케이션과 모델링 패러다임을 촉발할 것이라고 믿습니다. 여기에는 소규모 모델의 개선 및 교육을 가능하게 하는 합성 데이터 생성과 오픈 소스에서 이 규모로 달성된 적이 없는 기능인 모델 경량화가 포함됩니다.
이 최신 릴리스의 일환으로 8B 및 70B 모델의 업그레이드된 버전을 소개합니다. 이러한 모델은 다국어이며 128K의 상당히 긴 컨텍스트 길이, 최첨단 도구 사용 및 전반적으로 더 강력한 추론 기능이 있습니다. 이를 통해 최신 모델은 장문 텍스트 요약, 다국어 대화 에이전트 및 코딩 어시스턴트와 같은 고급 사용 사례를 지원할 수 있습니다. 또한 라이선스를 변경하여 개발자가 405B를 포함한 Llama 모델의 출력을 사용하여 다른 모델을 개선할 수 있도록 했습니다. 오픈 소스에 대한 우리의 헌신에 따라 오늘부터 이러한 모델을 llama.meta.com과 Hugging Face에서 다운로드할 수 있도록 커뮤니티에 제공하고 광범위한 파트너 플랫폼 생태계에서 즉시 개발할 수 있도록 제공합니다.
Model evaluations
이번 릴리스에서는 다양한 언어에 걸친 150개 이상의 벤치마크 데이터 세트에서 성능을 평가했습니다. 또한, 실제 시나리오에서 Llama 3.1을 경쟁 모델과 비교하는 광범위한 휴먼 평가를 수행했습니다. 실험 평가에 따르면, 플래그십 모델은 GPT-4, GPT-4o, Claude 3.5 Sonnet을 포함한 다양한 작업에서 선두적인 파운데이션 모델과 경쟁력이 있는 것으로 나타났습니다. 또한, 더 작은 모델은 유사한 수의 매개변수를 가진 폐쇄형 및 개방형 모델과 경쟁력이 있습니다.


Model Architecture
지금까지 가장 큰 모델인 Llama 3.1 405B를 15조 개 이상의 토큰으로 훈련하는 것은 큰 과제였습니다. 이 규모로 훈련 실행을 가능하게 하고 합리적인 시간 내에 결과를 얻기 위해 전체 훈련 스택을 상당히 최적화하고 모델 훈련을 16,000개가 넘는 H100 GPU로 밀어올렸고, 마침내 405B는 이 규모로 훈련된 최초의 Llama 모델이 되었습니다.

이 문제를 해결하기 위해, 우리는 모델 개발 프로세스를 확장 가능하고 간단하게 유지하는 데 중점을 둔 디자인 선택을 했습니다.
- 우리는 훈련 안정성을 극대화하기 위해 mixture-of-experts model보다는 사소한 적응을 거친 standard decoder-only transformer model 아키텍처를 선택했습니다.
- 우리는 각 라운드에서 supervised fine-tuning과 direct preference 최적화를 사용하는 반복적인 post-training 절차를 채택했습니다. 이를 통해 각 라운드에 대해 최고 품질의 합성 데이터를 생성하고 각 기능의 성능을 개선할 수 있었습니다.
이전 버전의 Llama와 비교했을 때, 우리는 사전 및 사후 학습에 사용하는 데이터의 양과 질을 모두 개선했습니다. 이러한 개선 사항에는 사전 학습 데이터에 대한 보다 신중한 사전 처리 및 큐레이션 파이프라인 개발, 보다 엄격한 품질 보증 개발, 사후 학습 데이터에 대한 필터링 접근 방식이 포함됩니다.
언어 모델의 확장 법칙에 따라 예상대로, 새로운 플래그십 모델은 동일한 절차를 사용하여 학습한 소규모 모델보다 성능이 뛰어납니다. 또한 405B 매개변수 모델을 사용하여 소규모 모델의 사후 학습 품질을 개선했습니다.
405B 규모의 모델에 대한 대규모 프로덕션 추론을 지원하기 위해 모델을 16비트 (BF16)에서 8비트 (FP8) 수치로 양자화하여 필요한 컴퓨팅 요구 사항을 효과적으로 낮추고 단일 서버 노드 내에서 모델을 실행할 수 있도록 했습니다.
Instruction and chat fine-tuning
Llama 3.1 405B를 통해 우리는 높은 수준의 안전성을 보장하면서 사용자 지침에 대한 모델의 유용성, 품질 및 자세한 지침 따르기 기능을 개선하기 위해 노력했습니다. 가장 큰 과제는 더 많은 기능, 128K 컨텍스트 창 및 모델 크기 증가를 지원하는 것이었습니다.
훈련 후, 우리는 사전 훈련된 모델 위에 여러 라운드의 정렬을 수행하여 최종 채팅 모델을 생성합니다. 각 라운드에는 Supervised Fine-Tuning (SFT), Rejection Sampling (RS), Direct Preference Optimization (DPO)이 포함됩니다. 우리는 합성 데이터 생성을 사용하여 대부분의 SFT 예제를 생성하고 여러 번 반복하여 모든 기능에 걸쳐 점점 더 높은 품질의 합성 데이터를 생성합니다. 또한 여러 데이터 처리 기술에 투자하여 이 합성 데이터를 최고 품질로 필터링합니다. 이를 통해 기능 전반에 걸쳐 미세 조정 데이터의 양을 확장할 수 있습니다.
우리는 모든 기능에 걸쳐 고품질의 모델을 생성하기 위해 데이터를 신중하게 균형 잡습니다. 예를 들어, 우리는 128K 컨텍스트로 확장하더라도 짧은 컨텍스트 벤치마크에서 모델의 품질을 유지합니다. 마찬가지로, 우리의 모델은 안전 완화책을 추가하더라도 최대한 유용한 답변을 계속 제공합니다.
The Llama system
Llama 모델은 항상 외부 도구 호출을 포함하여 여러 구성 요소를 조율할 수 있는 전체 시스템의 일부로 작동하도록 의도되었습니다. 저희의 비전은 개발자에게 비전과 일치하는 맞춤형 오퍼링을 설계하고 생성할 수 있는 유연성을 제공하는 더 광범위한 시스템에 대한 액세스를 제공하기 위해 파운데이션 모델을 넘어서는 것입니다. 이러한 생각은 작년에 핵심 LLM 외부의 구성 요소의 통합을 소개했을 때 시작되었습니다.
모델 계층을 넘어 AI를 책임감 있게 개발하고 다른 사람들이 그렇게 할 수 있도록 돕기 위한 지속적인 노력의 일환으로 여러 샘플 애플리케이션을 포함하고 다국어 안전 모델인 Llama Guard 3 및 프롬프트 주입 필터인 Prompt Guard와 같은 새로운 구성 요소를 포함하는 전체 참조 시스템을 출시합니다. 이러한 샘플 애플리케이션은 오픈 소스이며 커뮤니티에서 구축할 수 있습니다.
이 라마 시스템 비전의 구성 요소 구현은 여전히 단편적입니다. 그래서 저희는 업계, 스타트업 및 더 광범위한 커뮤니티와 협력하여 이러한 구성 요소의 인터페이스를 더 잘 정의하는 데 도움을 주기 시작했습니다. 이를 지원하기 위해 GitHub에서 "Llama Stack"이라고 부르는 것에 대한 RFC를 발표합니다. Llama Stack은 표준 툴체인 구성 요소 (미세 조정, 합성 데이터 생성) 및 에이전트 애플리케이션을 빌드하는 방법에 대한 표준화되고 의견이 있는 인터페이스 세트입니다. 이것이 생태계 전반에 채택되어 상호 운용성이 더 쉬워지기를 바랍니다.
제안을 개선할 수 있는 방법과 피드백을 환영합니다. Llama를 중심으로 생태계를 성장시키고 개발자와 플랫폼 제공자의 장벽을 낮추게 되어 기쁩니다.
Openness drives innovation
폐쇄형 모델과 달리 Llama 모델 가중치는 다운로드하여 이용할 수 있습니다. 개발자는 자신의 요구 사항과 애플리케이션에 맞게 모델을 완전히 사용자 정의하고, 새로운 데이터 세트에서 학습하고, 추가 미세 조정을 수행할 수 있습니다. 이를 통해 더 광범위한 개발자 커뮤니티와 전 세계가 생성 AI의 힘을 더욱 완벽하게 실현할 수 있습니다. 개발자는 애플리케이션을 완벽하게 사용자 정의하고 on-prem, 클라우드 또는 개인 컴퓨터를 포함한 모든 환경에서 실행할 수 있으며, Meta와 데이터를 공유하지 않아도 됩니다.
많은 사람이 폐쇄형 모델이 더 비용 효율적이라고 주장할 수 있지만, Artificial Analysis의 테스트에 따르면 Llama 모델은 업계에서 토큰 당 가장 낮은 비용을 제공합니다. 그리고 Mark Zuckerberg가 언급했듯이 오픈 소스는 전 세계의 더 많은 사람들이 AI의 이점과 기회에 액세스할 수 있도록 하고, 그 힘이 소수의 손에 집중되지 않으며, 이 기술이 사회 전반에 보다 균등하고 안전하게 배포될 수 있도록 보장합니다. 그렇기 때문에 우리는 오픈 액세스 AI가 업계 표준이 되는 길로 나아가는 단계를 계속 밟고 있습니다.
우리는 커뮤니티가 과거 Llama 모델을 사용하여 놀라운 것을 구축하는 것을 보았습니다. 여기에는 Llama로 구축되어 WhatsApp 및 Messenger에 배포된 AI 스터디 buddy, 임상 의사 결정을 안내하도록 설계된 의료 분야에 맞게 조정된 LLM, 브라질의 의료 비영리 스타트업이 포함됩니다. 이 스타트업은 의료 시스템이 환자의 입원에 대한 정보를 데이터 보안 방식으로 구성하고 전달하는 것을 더 쉽게 만듭니다. 오픈 소스의 힘 덕분에 그들이 최신 모델로 무엇을 구축할지 기대가 큽니다.
Building with Llama 3.1 405B
일반 개발자에게 405B 규모의 모델을 사용하는 것은 도전적인 일입니다. 매우 강력한 모델이기는 하지만, 이를 사용하려면 상당한 컴퓨팅 리소스와 전문 지식이 필요하다는 것을 알고 있습니다. 커뮤니티와 이야기를 나누었고, 생성적 AI 개발에는 모델을 촉구하는 것 이상의 것이 많다는 것을 깨달았습니다. 다음을 포함하여 모든 사람이 405B를 최대한 활용할 수 있도록 하고자 합니다.
- 실시간 및 일괄 추론
- Supervised fine-tuning
- 특정 애플리케이션에 대한 모델 평가
- 지속적인 사전 학습
- Retrieval-Augmented Generation (RAG)
- 함수 호출
- 합성 데이터 생성
여기서 Llama 생태계가 도움이 될 수 있습니다. 개발자는 첫날부터 405B 모델의 모든 고급 기능을 활용하고 즉시 빌드를 시작할 수 있습니다. 개발자는 또한 사용하기 쉬운 합성 데이터 생성과 같은 고급 워크플로를 탐색하고, 모델 경량화를 위한 turnkey 지침을 따르고, AWS, NVIDIA, Databricks를 포함한 파트너의 솔루션으로 원활한 RAG를 활성화할 수 있습니다. 또한 Groq는 클라우드 배포를 위해 저지연 추론을 최적화했으며 Dell은 on-prem 시스템에 대해서도 유사한 최적화를 달성했습니다.

우리는 vLLM, TensorRT, PyTorch와 같은 주요 커뮤니티 프로젝트와 협력하여 커뮤니티가 프로덕션 배포를 준비할 수 있도록 첫날부터 지원을 구축했습니다.
우리는 405B의 출시가 이 규모의 모델에 대한 추론과 미세 조정을 보다 쉽게 만들고 모델 경량화의 다음 물결을 가능하게 하기 위해 더 광범위한 커뮤니티에서 혁신을 촉진하기를 바랍니다.
Try the Llama 3.1 collection of models today
커뮤니티가 이 작업으로 무엇을 할지 기대됩니다. 다국어 지원과 증가된 컨텍스트 길이를 사용하여 도움이 되는 새로운 경험을 구축할 수 있는 잠재력이 매우 큽니다. Llama Stack과 새로운 안전 도구를 통해 오픈 소스 커뮤니티와 함께 책임감 있게 계속 구축할 수 있기를 기대합니다. 모델을 출시하기 전에, 레드팀을 통한 사전 배포 위험 발견 연습과 안전 미세 조정을 포함한 여러 가지 조치를 통해 잠재적 위험을 식별, 평가 및 완화하기 위해 노력합니다. 예를 들어, 외부 및 내부 전문가와 광범위한 레드팀을 수행하여 모델을 스트레스 테스트하고 예상치 못한 사용 방법을 찾습니다. (이 블로그 게시물에서 Llama 3.1 모델 컬렉션을 책임감 있게 확장하는 방법에 대해 자세히 알아보세요.)
지금까지 가장 큰 모델이기는 하지만, 앞으로 더 많은 기기 친화적 크기, 추가적인 modalities, 에이전트 플랫폼 계층에 대한 더 많은 투자를 포함하여 탐색할 새로운 영역이 많이 있다고 생각합니다. 언제나 그렇듯이, 커뮤니티가 이러한 모델로 구축할 모든 놀라운 제품과 경험을 기대합니다.
이 작업은 AI 커뮤니티 전반의 파트너의 지원을 받았습니다. 다음 사항에 감사드립니다 (알파벳순): Accenture, Amazon Web Services, AMD, Anyscale, CloudFlare, Databricks, Dell, Deloitte, Fireworks.ai, Google Cloud, Groq, Hugging Face, IBM WatsonX, Infosys, Intel, Kaggle, Microsoft Azure, NVIDIA, OctoAI, Oracle Cloud, PwC, Replicate, Sarvam AI, Scale.AI, SNCF, Snowflake, Together AI, UC Berkeley의 Sky Computing Lab에서 개발한 vLLM 프로젝트.
'IT와 개발 > AI 이야기' 카테고리의 다른 글
| OpenAI: SearchGPT Prototype (1) | 2024.08.20 |
|---|---|
| Figure 02 (0) | 2024.08.06 |
| GPT-4o mini: 비용 효율적인 지능 향상 (1) | 2024.07.23 |
| Stable Diffusion 3 출시 (1) | 2024.07.09 |
| Apple WWDC 2024 (1) | 2024.07.02 |



