10억 미만의 파라미터로 막대한 컴퓨팅 자원을 요구하는 대형 LLM인 ChatGPT와 비슷하거나 뛰어난 성능을 보이는 새로운 코드 기반 LLM 모델이 소개 되었습니다.
다양한 벤치마크에서 동등한 파라미터를 가진 LLM이나 그 이상의 컴퓨팅 파워를 요구하는 LLM 대비 높은 성능을 보이고 있으며, 기본 버전과 채팅 버전을 모두 오픈 소스로 제공하고 있습니다.
오랜만에 출시된 코드 기반 LLM으로 오픈 소스 기반, 그리고 적은 파라미터로 좋은 성능인 것을 강조하고 있습니다. 아무래도 개발 기업의 경우 라이선스 문제나 내부 기술 유출로 클라우드 기반 LLM을 사용하기에는 결정에 고민이 필요할 겁니다.
최근들어 많은 LLM 기업들이 오픈 소스 기반을 내세우고 있으며, 온 디바이스를 위해 모델의 경량화와 성능 향상을 지속적으로 연구하는 모습을 보여주고 있습니다.
사용자 입장에서는 아주 좋은 소식입니다. 새로운 코드 기반 LLM 모델을 경험해 보세요.
출처: Meet Yi-Coder: A Small but Mighty LLM for Code - 01.AI Blog (01-ai.github.io)
01.AI Blog
01-ai.github.io
소개
Yi-Coder는 100억 개 미만의 매개변수로 최첨단 코딩 성능을 제공하는 일련의 오픈소스 코드 Large Language Model (LLM)입니다.
1.5B 및 9B 매개변수의 두 가지 크기로 제공되는 Yi-Coder는 효율적인 추론과 유연한 학습을 위해 설계된 기본 버전과 채팅 버전을 모두 제공합니다. 특히, Yi-Coder-9B는 Yi-9B를 기반으로 GitHub의 저장소 수준 코드 모음에서 꼼꼼하게 수집한 2.4T의 고품질 토큰과 CommonCrawl에서 필터링한 코드 관련 데이터를 추가하여 구축되었습니다.
Yi-Coder의 주요 기능은 다음과 같습니다.
- 52개 주요 프로그래밍 언어에 걸쳐 2.4조 개의 고품질 토큰으로 사전 학습을 계속합니다.
- 긴 컨텍스트 모델링: 최대 128K 토큰의 컨텍스트 창을 통해 프로젝트 수준의 코드 이해 및 생성이 가능합니다.
- 작지만 강력함: Yi-Coder-9B는 CodeQwen1.5 7B 및 CodeGeex4 9B와 같이 100억 개 미만의 매개변수를 가진 다른 모델보다 성능이 뛰어나며 DeepSeek-Coder 33B와 동등한 성능을 달성합니다.

Yi-Coder는 인상적인 코딩 성능을 제공합니다
LiveCodeBench
LiveCodeBench는 LLM을 위한 경쟁 프로그래밍에 대한 포괄적이고 공정한 평가를 제공하도록 설계된 공개 플랫폼입니다. LeetCode, AtCoder, CodeForces와 같은 경쟁 플랫폼에서 실시간으로 새로운 문제를 수집하여 역동적이고 포괄적인 벤치마크 라이브러리를 형성합니다. Yi-Coder의 학습 데이터 마감일이 2023년 말이기 때문에 데이터 오염이 발생하지 않도록 2024년 1월부터 9월까지의 문제를 선택하여 테스트했습니다.
아래 그래프에서 보듯이, Yi-Coder-9B-Chat은 23.4%라는 인상적인 Pass Rate를 달성하여 10B 미만 매개변수 중에서 20%를 넘는 유일한 모델이 되었습니다. 아래 모델들의 성능보다 높은 것을 확인할 수 있습니다.
- DeepSeek-Coder-33B-Instruct(약칭 DS-Coder) 22.3%
- CodeGeex4-All-9B 17.8%
- CodeLLama-34B-Instruct 13.3%
- CodeQwen1.5-7B-Chat 12%

HumanEval, MBPP and CRUXEval-O
콘테스트 수준의 평가 외에도 HumanEval, MBPP, CRUXEval-O와 같은 인기 있는 벤치마크를 선택하여 모델의 기본 코드 생성 및 추론 능력을 평가했습니다. 아래에 표시된 평가 결과는 Yi-Coder가 이 세 가지 과제에서 뛰어난 성과를 달성했음을 나타냅니다. 구체적으로 Yi-Coder-9B-Chat은 HumanEval에서 85.4%, MBPP에서 73.8%의 합격률을 달성하여 다른 코드 LLM을 능가했습니다. 게다가 Yi-Coder 9B는 CRUXEval-O에서 50%의 정확도를 돌파한 최초의 오픈소스 코드 LLM이 되었습니다.

Yi-Coder는 코드 편집 및 완성에 뛰어납니다.
CodeEditorBench
Yi-Coder의 코드 수정 작업 능력을 평가하기 위해 CodeEditorBench를 활용했는데, 디버깅, 번역, 언어 전환, 코드 연마의 네 가지 핵심 영역을 포괄합니다. 아래 차트에서 볼 수 있듯이 Yi-Coder-9B는 오픈소스 코드 LLM 중에서 인상적인 평균 승률을 달성하여 primary 및 plus 하위 집합 모두에서 DeepSeek-Coder-33B-Instruct 및 CodeQwen1.5-7B-Chat보다 지속적으로 우수한 성과를 보였습니다.

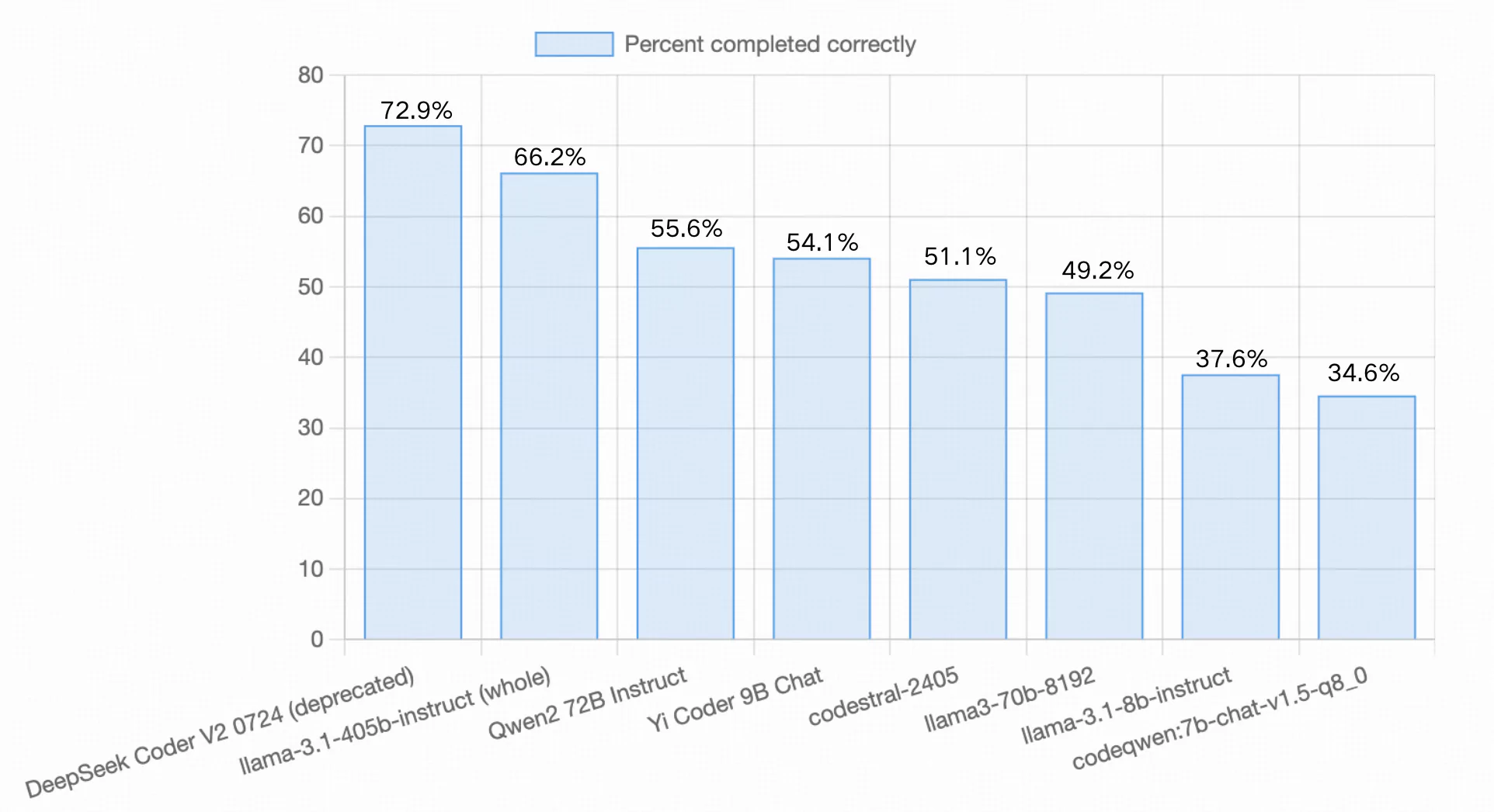
Aider LLM Leaderboards
Aider의 코드 편집 벤치마크는 Exercism에서 얻은 133개 코딩 연습에서 Python 소스 파일을 수정하는 LLM의 능력을 평가합니다. 이 평가는 모델의 새로운 코드 생성 능력을 테스트할 뿐만 아니라 해당 코드를 기존 코드베이스에 원활하게 통합하는 능력도 결정합니다. 또한 모델은 프로세스 중에 인간의 안내가 필요 없이 모든 변경 사항을 자율적으로 적용해야 합니다.
모델 출시 후 Yi-Coder-9B-Chat은 54.1%의 exercises를 성공적으로 완료하여 Qwen2-72B Instruct (55.6%)와 codestral-2405 (51.1%) 사이에 위치했으며, LLama-3.1-8B-Instruct (37.6%)와 CodeQwen1.5-7B-Chat (34.6%)과 같은 유사한 규모의 모델보다 훨씬 우수한 성과를 보였습니다.
CrossCodeEval
최신 AI 기반 IDE 도구의 중요한 사용 사례인 코드 완성 측면에서 Yi-Coder는 또한 뛰어난 성능을 보여주었습니다. 코드 생성과 달리, cross-file code completion은 모델이 여러 파일에 걸쳐 있는 저장소에 액세스하고 이해해야 하며, 수많은 cross-file 종속성이 있어야 합니다. 우리는 이 평가를 위해 두 가지 다른 시나리오, 즉 관련 컨텍스트를 검색하는 경우와 그렇지 않은 경우에서 CrossCodeEval 벤치마크를 고려했습니다.
아래 차트의 결과는 Yi-Coder가 Python과 Java 데이터 세트 모두에 대해 검색 및 비검색 시나리오에서 비슷한 규모의 다른 모델보다 성능이 우수하다는 것을 보여줍니다. 이러한 성공은 더 긴 컨텍스트 길이를 가진 소프트웨어 저장소 수준 코드 corpora에 대한 학습을 통해 Yi-Coder가 장기 종속성을 효과적으로 포착하여 뛰어난 성능에 기여할 수 있음을 입증합니다.


Yi-Coder는 128K 긴 컨텍스트를 모델링할 수 있습니다.
Needle in the code
Yi-Coder의 긴 컨텍스트 모델링 기능을 테스트하기 위해, 우리는 128K 길이의 시퀀스를 사용하여 "Needle in the code"라는 합성 작업을 만들었습니다. 이는 CodeQwen1.5 평가에서 사용된 64K 길이의 시퀀스의 두 배 길이입니다. 이 작업에서 간단한 사용자 지정 함수가 긴 코드베이스에 무작위로 삽입되고, 모델은 코드베이스 끝에서 함수를 재현할 수 있는지 여부에 대해 테스트됩니다. 이 평가의 목적은 LLM이 긴 컨텍스트에서 핵심 정보를 추출할 수 있는지 평가하여 긴 시퀀스를 이해하는 기본적인 능력을 반영하는 것입니다.
아래 차트의 모든 녹색 결과는 Yi-Coder-9B가 128K 길이 범위 내에서 이 작업을 완벽하게 완료했음을 나타냅니다.

Yi-Coder는 수학적 추론에서 빛을 발하다
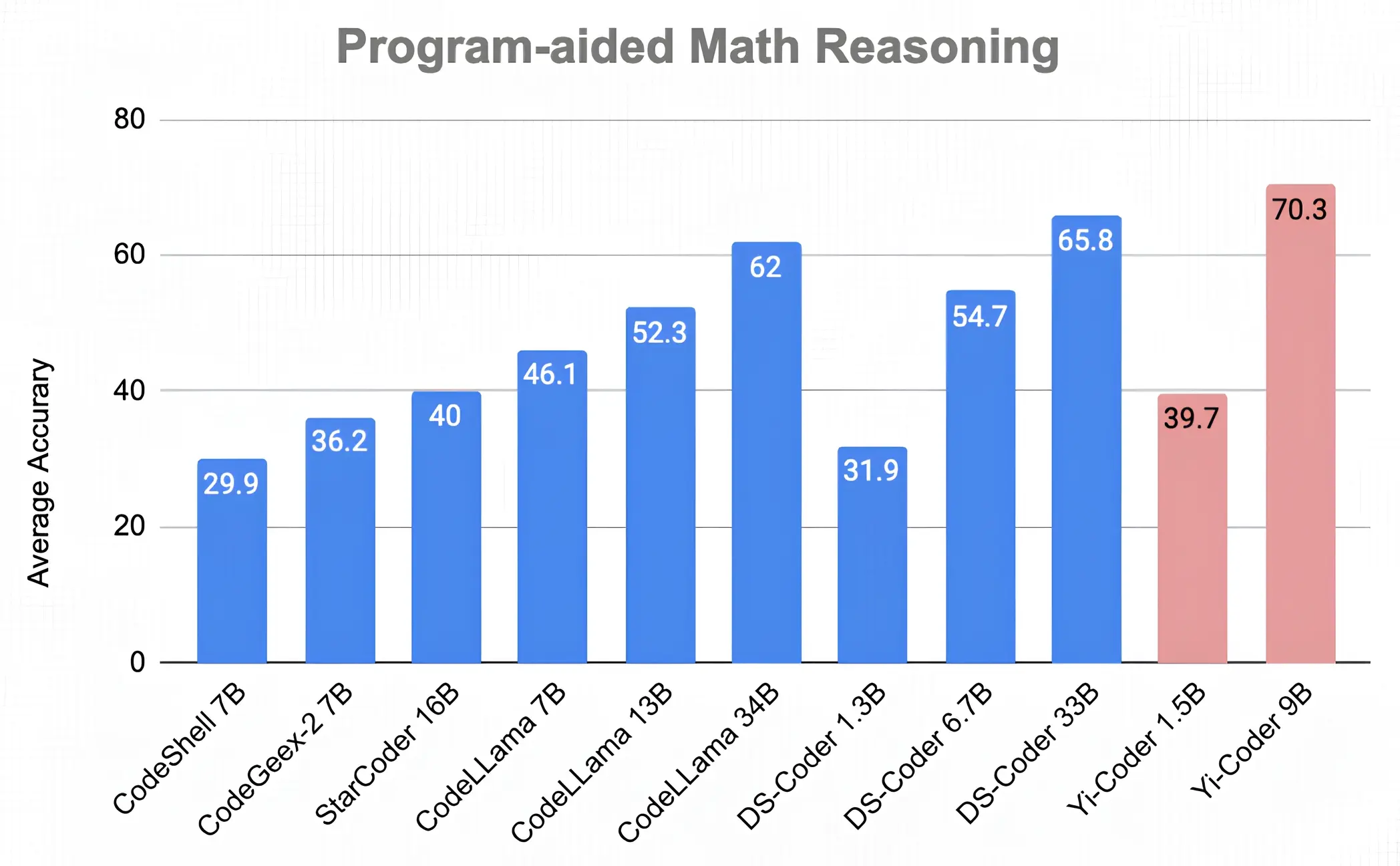
Progam-Aid Math Reasoning
DeepSeek-Coder에 대한 이전 연구에서는 강력한 코딩 기능이 프로그래밍을 통해 문제를 해결함으로써 수학적 추론을 향상시킬 수 있음을 보여주었습니다. 여기에서 영감을 얻어, 우리는 프로그램 지원 설정 (즉, PAL: Program-aided Language Models)에서 7가지 수학 추론 벤치마크에서 Yi-Coder를 평가했습니다. 이러한 벤치마크 각각에서 모델은 Python 프로그램을 생성한 다음 프로그램을 실행하여 최종 답을 반환하도록 요청받습니다.
아래 그림에 제시된 평균 정확도 점수는 Yi-Coder-9B가 DeepSeek-Coder-33B의 65.8%를 능가하는 70.3%의 놀라운 정확도를 달성한다는 것을 보여줍니다.
결론
저희는 Yi-Coder 1.5B/9B를 오픈 소스화하여 커뮤니티에 기본 버전과 채팅 버전을 모두 제공합니다. 비교적 작은 크기에도 불구하고 Yi-coder는 기본 및 경쟁 프로그래밍, 코드 편집 및 리포 수준 완성, 긴 컨텍스트 이해, 수학적 추론을 포함한 다양한 작업에서 놀라운 성능을 보여줍니다. 저희는 Yi-Coder가 소규모 코드 LLM의 경계를 넓히고 소프트웨어 개발을 가속화하고 혁신할 수 있는 사용 사례를 제공할 수 있다고 믿습니다.
Yi-Coder 시리즈 모델은 Yi 오픈 소스 제품군의 일부입니다. Transformers, Ollama, vLLM 및 기타 프레임워크와 함께 Yi-Coder를 사용하는 방법에 대한 자세한 내용은 Yi-Coder README를 참조하세요.
저희는 개발자가 이러한 리소스를 탐색하고 Yi-Coder를 프로젝트에 통합하여 강력한 기능을 직접 경험하기를 권장합니다. Discord에 참여하거나 문의 사항이나 토론 사항이 있으면 yi@01.ai로 이메일을 보내주세요.
감사합니다.
01.AI의 DevRel
'IT와 개발 > AI 이야기' 카테고리의 다른 글
| NVIDIA CEO Jensen Huang과의 대화 - AI와 에너지의 미래 (11) | 2024.10.08 |
|---|---|
| The Intelligence Age (14) | 2024.10.01 |
| AI Apocalypse: 80% of Projects Crash and Burn (10) | 2024.09.17 |
| Llama is the leading engine of AI innovation (10) | 2024.09.10 |
| Zed AI 소개 (4) | 2024.09.03 |



